Tianshu Huang / Open Source Portfolio

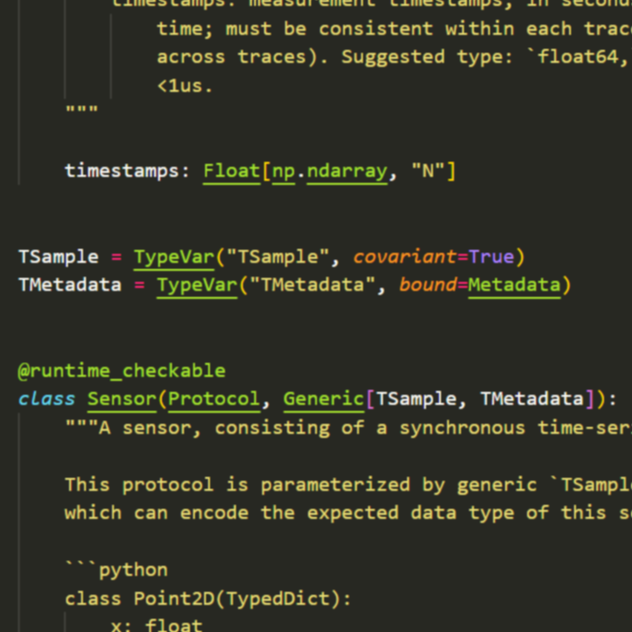
Since my research interests focus on nonstandard problems which are generally difficult for a human to interpret — and sanity-check, my research philosophy places a strong emphasis on writing modular, auditable code. As domains like radar spectrum and computer systems lie outside of the machine learning mainstream, tackling these problems also requires a substantial engineering investment in novel infrastructure for data collection, processing, and experimentation.
Some particular up-and-coming1 technologies for the python-ML ecosystem which I believe in strongly include:
Type Annotations & Type Checking
Between the core python language type specification, now-standard static type checking with tools like pyright, array annotation with jaxtyping, and runtime type checking with beartype, the python gradual typing playbook has just about gotten to the point where it can cover the majority of machine learning use cases.
- Rigorous adherence to type annotation and type checking best practices eliminates many common classes of bugs2, replacing them with
TypeErrorswhich are raised at function boundaries. - Python's type system also provides a standardized and mechanically-verifiable way of describing sensor data types.
Jax
Compared to it's contemporary competitors Pytorch and Tensorflow, Jax has an (at least in my view) incredibly elegant and powerful programming model which revolves around functional programming. It's also natively built around a powerful compiler stack which pretty much guarantees that your code will be fast — if you can get it to compile3.
- Other key benefits including full support for all (un)signed integer, float, and complex types ... unlike pytorch.
- This does come overhead in that functional programming can be difficult to get used to for those without training4.
Unfortunately, due to Pytorch's status as the de-facto standard framework for the community, my current work is all pytorch-based.
Active Projects
My current active projects are centered around the RadarML project, which seeks to build a software ecosystem for learning on mmWave radar spectrum.
-

abstract interface for composable dataloaders and preprocessing pipelines
-

python interface for collecting raw time signal data from TI mmWave radars
-
our "third generation5" radar spectrum data collection system
-
the neural radar development kit for deep learning on multimodal radar data






Paper Artifacts
-
29 hours of radar (time signal), lidar, and camera data
-
original research code for GRT (ICCV Oral '25)
-
instrumentation tooling & data analysis for Beanstalk (OOPSLA '25)
-
standalone jax-based implementation & dataset for DART (CVPR Oral '24)
-
jax-based implementation and dataset for Pitot (MLSys '25)
-
implementation for Optimizer Amalgamation (ICLR '22) using the
l2oframework

Deprecated Projects
-
Tools like
uv,ruff,mkdocs,mkdocstringsare already de-facto standards for new projects, and don't need any promoting. ↩ -
E.g.,
ValueError: shape mismatchor out-of-memory errors induced by unintended shape broadcasting ↩ -
In this way, Jax is very much the Rust of Machine Learning: it takes some effort to convince the compiler your code can run on a GPU, but if you can do it, you're guaranteed to avoid many types of performance issues that you'd otherwise get on an interpreter-first framework like Pytorch. ↩
-
Fortunately, CMU is a functional programming school, so it's no problem finding students here who can handle it! ↩
-
"First generation": a non-automated solution using only officially supported TI software; "Second generation": a partially automated and somewhat modular system relying on official TI software, with some custom implementations; "Third generation": a fully automated, modular, and tightly-integrated linux-based data collection system without any TI software dependencies on the data collection computer ↩↩
-
Jax's functional programming "differentiation is a higher order function" approach makes optimization meta-learning vastly simpler to implement, completely eliminating the need for such a complicated framework. ↩
-
This library has been abandoned since it turns out there is not much demand for Bayesian Clustering algorithms. In particular, these methods are only really suitable for low-dimension (<50) moderate-data (>100, <10000) settings where powerful, fully-automated clustering is required, of which there simply aren't that many. ↩